
Introduction
In today’s article, I would like to tell you about a domain I find absolutely fascinating: Machine Learning. This article will show you how I implemented the NEAT Algorithm to play Super Mario Bros. on an emulated Nintendo Entertainment System (NES).
This article will cover theoretical parts, as well as the implementation I made in Rust. I’ve also adapted the project to compile it in Web Assembly, so you can see a fully functional demonstration of neural networks playing to the NES. The whole source code is available on my forgejo instance. At the end of the article, you can find some statistics I found interesting about the neuroevolution process.
Before diving in this article, I would like to personnally thank Lulu for the compute resources and the interest he had on the project. You can find his personal projects on his forgejo instance: https://git.az4aaz.xyz/explore/repos. I would also like to thank Roro, for the theoretical resources he shared with me. This article is just a bunch of things I’ve found really interesting to share with you from those resources, reformulated with my hands on the keyboard (no AI there). If you find this article boring or not covering parts you would like to dig in, please go directly to the bibliography section and find the articles bellow (mainly the deeplearning book, which is a treasure of knowledge Roro decided to share with me). If you need more information about the NEAT algorithm in particular, please find the article in the bibliography.
Disclaimer
I’m not associated with Nintendo Co. Ltd. I hope what I’m doing is legal, and if it’s not, meh, I suppose I’m sorry ?
Theory
What is the NEAT Algorithm?
NEAT stands for Neuroevolution of Augmenting Topologies. The algorithm it describes was designed to mimic the Evolution Theory, by Darwin. But to understand why and how it works, let’s dig in to what a Neural Network is.
Brief Introduction to Machine Learning And Neural Networks
Machine Learning is a field of Computer Science dedicated to the solving of problems difficult to describle formally, that most humans feel intuitive: e.g. recognizing a face, describe a drawing, suggesting an audio track. The idea behind machine learning is to let the computer learn from its own experience in order to avoid the need of a human operator to describe sequentially the steps to solve the problem.
To solve a problem using ML, we will need to extract features from the problem. Let’s take the example of playing Super Mario Bros. The screen of the NES contains lots of pixels, which, if taken individually, don’t give any relevant information. But the position of monsters or obstacles will be useful if we want the algorithm to finish the level: they are features (i.e. pertinent pieces of information describing the problem). The first step of solving the problem is therefore to define the right set of features. Those features are then used as inputs, to compute a reponse to the problem. In our example, the response will be a mathematical function corresponding to the reaction Mario should have to any obstacle. This reaction (formally called output) is wheather Mario has to jump, go left, right, down…
The output function $f$ has to approximate the value of $y$, the solution of the problem. $f$ will be computed by chaining other functions ($\sigma$, the sigmoid function, Rectified Linear Unit…, Hyperbolic Tangente etc.). The number of chained functions is called the depth of the neural network. That’s why if we consider there are a lot of chained functions, we talk about deep learning.
If you want to see an online demo of a classification problem (considered as difficult to describe formally), you can see the different functions we talked about in action right there : https://playground.tensorflow.org/
Why do we talk about Neural Networks?
The structure followed to solve the problem is inspired by neuroscience. We represent neural networks as graphs, every node applies a function as described bellow, and the values are mutilplied by a coefficient called weight while they go through a connection
The kind of neural network I’ve decided to tell you about is feed forward neural networks. A feed forward neural network lets information going from the input to the output, without allowing information to loop in the neural network. Recurrent Neural Networks allow this kind of process, letting a kind of memory emerge from the data recursion.
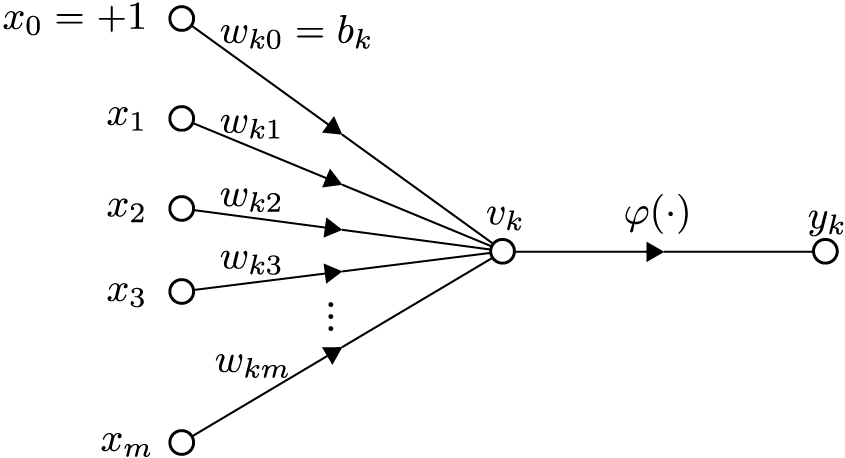
This illustration is from wikipedia. In this figure, you can see the input data, represented as $x_i$, the coefficients of the input vector, called $X$. $w_{k_i}$ is the weight associated to the connection $i$ and $v_k$ is the node $k$. The activation function is $\varphi$ and the output is given in the node $y_k$.
I can hear a question you might want to ask : why do we use vectors here ?. Well the answer is simple: to optimise the computation processus. In fact, nowadays, we have powerful GPUs able to perform matrix multiplication way faster than if it were done sequentially. So, instead of doing manually
| |
we simply perform the matrixial product $X \times W_k$ using vectorial units with CUDA (or any similar API) and then apply the activation function to the result we got.
Well, that’s what professionals do. I didn’t in my implementation, to simplify the algorithm, but maybe i’ll do it in the future (with an FPGA ? why not! -> this is a reference to a future article)
The RNN Approach
Basically, the first NEAT implementation was not recurrent. But the creator of this algorithm, Kenneth Stanley, clearly said implenting NEAT as a Recurrent Neural Network wasn’t in opposition with the process followed by the algorithm. This is how a RNN looks like :
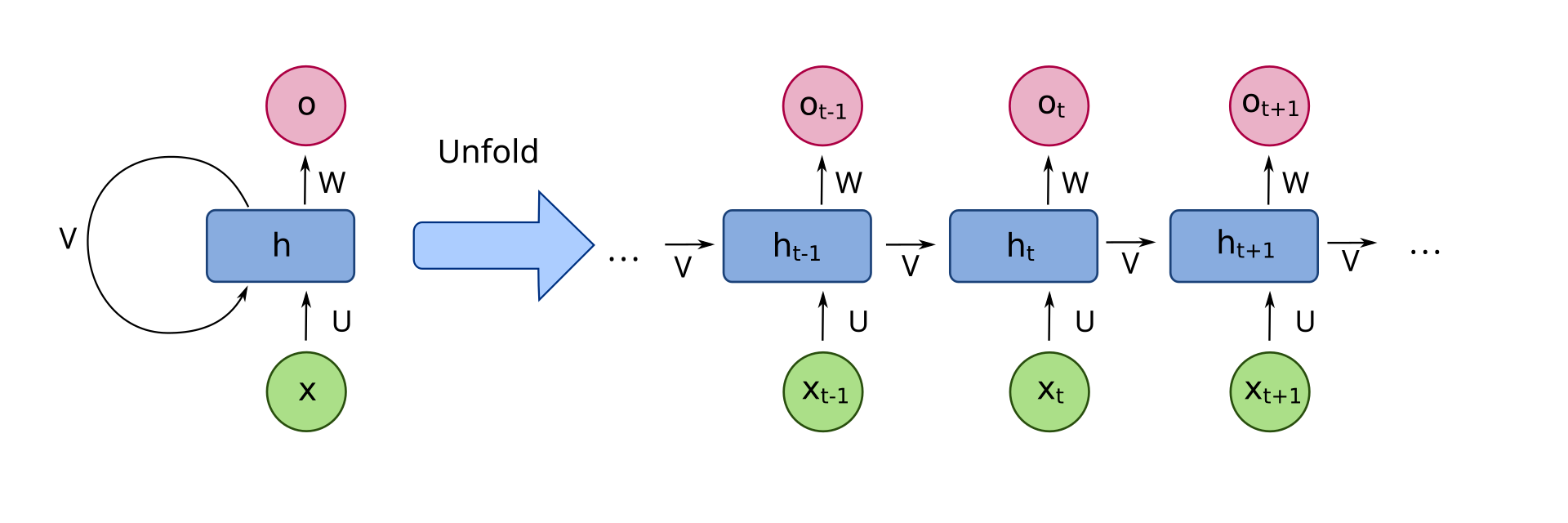
This illustration also came from Wikipedia. As you can see, we need to unfold the neural network in order to be able to evalute it, or in other terms, to get the output vector $Y$. We will see later that the process is similar for Feed Forward Neural Networks, as we need to apply a topological sort (i.e. finding out in which order we need to feed, or to compute the value assigned to each neuron). The main difference is in a RNN, the same neuron will have different values after being fed. But this example is just informative, as I decided to implement the NEAT algorithm with a Feed Forward approach to simplify the process of evalutation.
Where is the evolution you talked about ?
This is the main difference between classical neural networks and those implementing the NEAT algorithm. The NEAT algorithm is the following :
First, we create a population of randomly connected neural networks
We check how well each neural network is able to solve the problem, by giving a score to each of them (using a fitness function we’ll see later)
Then, we group the neural networks (also called individuals) in species, by checking how similar they are (unsing, similar connections, weights, etc.) species are subgroups used to preserve innovation (we will se how later)
Each individual inherits the score of the best individual of the species (we will see why)
The species getting a better score through iterations are preserved, the other ones are wiped out
Individuals in the surviving species reproduice and the offspring get mutations (a node or a connection can be added, a weight can be altered)
The algorithm starts again with the best individuals from this generation and the offspring, starting at step 1.
Let’s make it more clear.
At the step 0, we create a bunch of neural networks containing random connections / random weights (sometimes both, or we fully connect all the networks, it depends on the implementation). Then, we have to evalutate each neural network, and give it a score. This score is established by a fitness function. This function varies according to the problem we want to solve. In our example, the more Mario has walked a big $x$ distance on the level, the more the level is near to be finished. In other terms, we want to encourage the distance achieved by neural networks throught evolution. So the fitness function returns the $x$ distance the individual was able to walk.
In our case, the fitness function will spawn the emulator, extract the features, feed them to the neural network until Mario dies. Then, it will return the $x$ position mario achieved when Mario died.
If we wanted greedy neural networks, this function could return the number of coins earned.
The next big part is the speciation. To check if individuals belong to the same species, we compute the distance $\delta$ between the representant of a species and an individual. Before we continue on this principle, you need to know that every node and connection is identified by a number stored in a global database. Since we can add nodes and mutations to a neural network, we need to know if this new node or connection is an innovation or not. That’s why we keep track of those values globally, from the first to the last population. Let’s continue with the compatibility distance. This distance is computed as follow :
$$ \delta = c_1\cdot\frac{E}{N}+c_2\cdot\frac{D}{N}+c_3\cdot\bar{W} $$$N$ is the number of genes in the larger genome. This value is used to nomalise the distance. $c_1$, $c_2$ and $c_3$ are used to adjust the impact of :
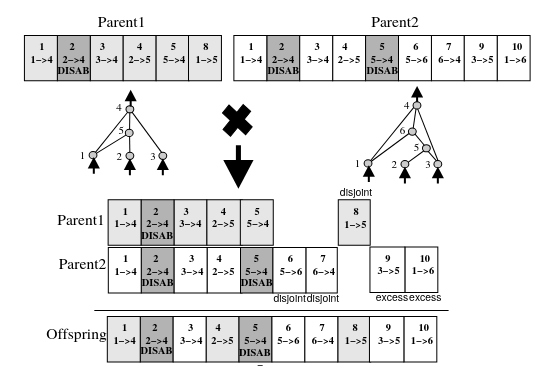
E : The number of excess genes. Excess genes are connections with a number not in the range of the id from the other genome
D : The number of disjoint genes. Disjoint genes are connections with an ID in the range of the other neural network, but not in its genotype.
$\bar{W}$ : The average weight difference
https://nn.cs.utexas.edu/downloads/papers/stanley.ec02.pdf
Why do we group individuals in species ? since we can change the properties of neural networks through mutations, we can, just by changing a weight, destroy the performance of the neural network getting mutated. This is really bad if we want to promote innovation, since this performance loss isn’t representative at long term. Therefore, we get the fitness from the best individual as the fitness for all the individuals in the same species.
The last important thing with NEAT is the crossover, or reproduction. The figure bellow show you how the genes are inherited from parents to the offspring. Disjoint and excess genes are innherited from the fitest parent, and matching genes are inherited randomly. If the fitness is equal, every gene is inherited randomly.
Speciation and gene tracking through a global database are the two things making the NEAT algorithm particularly efficient to preserve innovation.
The crossover process gives a solution to the competing convention problem or “what genes should I choose without loosing the benefits from evolution?”
What we’ve seen until there
Neural Networks are just a way to let a computer learn autonomously from a dataset, composed of features.
Neural Networks are made of nodes and connections, chaining simple functions (sigmoid, ReLu, tanh) and coefficients (weights $w_k$) to solve problems that seems intuitive and therefore difficult to explain formally, like recommanding a music or describing a painting.
Those graphs, or networks are called neural because they are inspired by neuroscience.
There are two main types of Neural Networks : Feed Forward Neural Networks (also misnamed Multilayer Perceptron Neural Networks but anyways) and Recurrent Neural Networks. This article will cover an implementation I’ve made of a Feed Foward one.
To feed a Neural Network or a neuron is to give it some input data.
To evaluate a Neural Network is to feed it and to get the output data.
The NEAT algorithm combines neural networks with evolution theory, using speciation and crossover to preserve innovation and to solve the competing conventions problem
If everything seems clear to you, we can continue (: If not, please refer to this book and articles :
- https://www.deeplearningbook.org/
- https://en.wikipedia.org/wiki/Feedforward_neural_network
- https://en.wikipedia.org/wiki/Recurrent_neural_network
- https://nn.cs.utexas.edu/downloads/papers/stanley.ec02.pdf
The implementation
Inspiration
The idea from this project is from a video I saw from the French Youtuber Laupok. I found this concept very innovative and wanted to do something similar by myself. I would like to thank Laupok, for his video, because it was the begining for me of a huge world built of discoveries and marvelous mathematical things.
Now we’re done with thanks, let’s hit the most interesting part !
The language
Rust, because it’s just beautiful and so well made. I also wanted webassembly support to be able to show you a little demo right there.
The architecture
To let a neural network play the NES, and in particular Super Mario Bros., we first need a NES. I didn’t build the NES core by myself, because I wanted to focus on the neuroevolution part. But this project helped my understand a lot how a NES works. The core is from the Tetanes Core library by lukexor. From this core, I built my own emulator. This emulator is a bit particular, since you can’t play with it. Its design was perhaps made for the neural network to play. Here is a part I found particularly interesting to show you this principle:
| |
Well, this is basically the emulator, with maybe some missing definitions, but the main idea is there.
As you can see, the screen is extracted from the NES, and is then sent as the input of the neural network. We have some temporizations, to stay at 60 fps (the NES was running at 60 fps). And you might ask “but you said those pixels, taken individually, didn’t make sense to train the neural network”. And that’s true.
Extracting Game Data From The NES
As I told you before, we need to extract features from the screen. I’ve decided to define the following features :
- Mario’s position
- Monsters’ position
- Blocks’ position
- Walkable, or “empty” positions (air)
| |
To extract those features, we need to dump the RAM of the console. Geathering information about Super Mario Bros. RAM map was a bit difficult, until I found maps on the internet :
- https://raw.githubusercontent.com/MrWint/smb-dis/master/smbdispal.asm
- https://datacrystal.tcrf.net/wiki/Super_Mario_Bros./RAM_map
To compute Mario’s absolute position, we get values from 0x006D and 0x0086. The value at 0x0086 contains the number of screens that have scrolled from the begining of the level, and the adress at 0x006D contains Mario’s position modulo 256. As the NES screen is 256 pixels width, we can say mario’s position is
$$\text{value at RAM[0x0086]} \cdot 256 + \text{value at RAM[0x006D]}$$From mario’s absolute position, we can compute the position of the left edge of the current screen (since the screen is loaded in the memory with a larger buffer than the screen size, we need to find out which part is in the current screen or not. In fact, the screen tiles are loaded in two pages, or two buffers, each matching the screen size ). The only piece information we need is Mario’s position in the screen, and it is stored at 0x03AD. So the left edge position is
$$\text{mario\_absolute\_x} - \text{RAM[0x03AD]}$$From there, we do not work anymore with pixels, but with tiles Mario’s screen is filled with tiles of dimension $16\times16$ pixels.

https://www.spriters-resource.com/nes/supermariobros/asset/52571/
We then extract tiles from the ram, and put the features in three layers. Each layers has the dimension of the screen in tiles, filled with zero for the walkable, or air part, and a value matching the position of the feature, in tiles.
To do so, we use the coords_to_ram function. It converts (x;y) tiles coordinates from the screen into a RAM adress :
| |
NEAT Implementation
I’ve decided to write my own library to implement the NEAT algorithm. You can find it here: https://git.anyn.one/Anynone/rennuos.git
This project contains to branches : a main one, designed to solve classical mathematical problems, and a maroil one, to play Super Mario Bros. on the NES.
One of the biggest problems I had was the training time. To solve it, I used chained threads. Instead of using classical scoped threads, I use an MPSC channel in each thread to tell if the thread has finished its work. If it is the case, a new thread spawns to evaluate a new neural network :
| |
The fitness function is the following :
| |
As you can see here, I also added a deadline, because some individuals just walked and stopped, wating for the game time to be over. This was a big time loss during evalutation. This line will progress slower than mario when it walks, but will never stop. When the line position is the same as Mario’s position, we stop evaluation there with mario’s current position.
The Result
This result is from 1605 generations of neuro evolutions, computed in 3 days, thanks to Lulu’s puter. You can select the best individual from the generation $i, i \in [0, 1605]$ and watch it play with an emulated NES directly on you web browser, by clicking on “run”.
You can find the source code of this web version in my forgejo : https://git.anyn.one/Anynone/maroil-webviewer
The whole project source code is here : https://git.anyn.one/Anynone/maroil
enjoy!
Bibliography
https://www.deeplearningbook.org/ https://nn.cs.utexas.edu/downloads/papers/stanley.ec02.pdf https://git.anyn.one/Anynone/rennuos.git https://www.spriters-resource.com/nes/supermariobros/asset/52571/ https://en.wikipedia.org/wiki/Feedforward_neural_network https://en.wikipedia.org/wiki/Recurrent_neural_network